











活用領域

ケモインフォマティクス
��(分子設計)
化学構造を数値化して物性・活性との間で機械学習を行い、合成前の化学構造から物性・活性や化学反応を予測するモデルを構築します。また目標の物性・活性を達成する化学構造やその反応経路を推定できます。

マテリアルズインフォマティクス
(材料設計)
実験データを学習し、未知の実験・製造条件から材料の物性・活性を予測するモデルを構築します。また原料の化合物から目標とする材料を得るための実験・製造条件を推定できます。

プロセスインフォマティクス
(プロセス設計・管理)
プロセスデータを用いて目標の材料を合成するための装置やプロセスを設計します。また、プラントのセンサーデータからリアルタイムでの測定が難しい因子を随時推定するソフトセンサーと呼ばれるシステムや、プラントの状態異常を検知するモデルを構築し、実運用できます。
機能のご紹介
データアクセス
表データ(CSV形式。数値と文字列の混合可)や化学構造データ(SMILES形式)といった、お手持ちのデータを簡単に読み込めます。
実験条件・化学構造生成
実験条件・化学構造の候補を数千、数万単位でも自動生成できます。
実験計画法
多数の実験条件の中から最初に実験する上で効果的な候補を統計的に絞れます。
記述子計算
化学構造を数値データ化します。単重合体や共重合体も取扱いできます。
データ可視化
各種統計グラフや低次元化により特徴量の分布や特徴量間の特徴を簡単に把握できます。
データ前処理
特徴量の変換・追加・削除を行い、モデル構築に適した形に調整できます。
回帰分析
様々なアルゴリズムの中から予測精度の高いモデルの構築検討ができます。また各特徴量の回帰係数、重要度が一覧化され、予測根拠を確認できます。
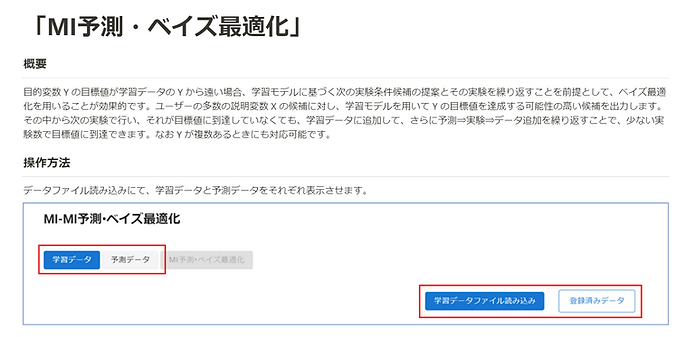
適応的実験計画法
既存の実験データに基づいて、次に実験する上で有効な候補が提案されます。
ベイズ最適化
適応的実験計画法において、目標値が学習データから遠いときの方法として効果的です。
時系列データ分析
時間変化しているデータを用いてモデルを構築し、リアルタイムに測定されたデータから随時予測でき、ソフトセンサー、異常検知を実運用できます。
モデル最適化
パラメータの自動最適化、および各種モデルの予測精度の比較が容易です。
逆解析
物性・活性の予測モデルを構築後、目標値を達成する条件を割り出せます。他サービスにはない直接的逆解析も実行できます。
欠損値補完
学習データの中に欠損部分がある際に、特徴量全体の情報から欠損値を自動推定します。
クラス分類
定性データを目的変数として、カテゴリー分類の予測が行えます。
混合物計算
原料の組成データと原料そのものの物性・性状データを掛け合わせて、各計算手法により新たな特徴量を算出します。
スペクトル
分析装置でのスペクトルやプロファイルの数値データを処理し、組成や物性予測を行えます。
試薬データベース
富士フイルム和光純薬(株)の49万種以上の化合物から候補試薬のデータ抽出を行い、物性・性状予測後、最適試薬の製品情報サイトに直接アクセスできます。
セキュリティ
サポート専門サイトをご用意
各セクションの使い方
豊富な手順書、トピックに合わせた技術資料を備え、操作の流れを動画で確認できます。
活用トレーニング
実践的な練習課題と模範解答動画を通じて、効果的にデータ解析・機械学習活用法を学習することができます。
